


更新日志🎉
2023-01-29 星期六
修正一些已知错误
调整文章布局结构
修正错别字词
2022-05-26 10:20:23 星期四
修正语言表达逻辑
删除/修改了错别字词
更新了部分配图
2022-08-02
修正错别字
修正语言表达逻辑
2022-08-22
- 还是修已知的正错别词语
Java集合解读
IDEA快捷键
查看源码:F4
进入实现:Ctrl+Alt+B(鼠标点击)
添加实现类:空格
显示图:Ctrl+Alt+Shift+U
概览
**说明:**以下内容的源码分析,如没有特别说明,均来自JDK8.
集合主要分为两组:单列集合和双列集合
但列集合一般是指存放单个对象的集合,而双列集合一般是以<k,v>键值对形式存放数据的集合。
Collection接口下有两个重要的子接口List,Set,他们的实现子类都是单列集合。
Map接口的实现子类有HashTable、HashMap、TreeMap,也都是双列集合。以下是集合类下两大主接口的类图关系。
Collection系

在Conllection接口下,派生出了三个主要的子接口,分别为无序集合
Set,队列Queue和有序集合List。在三大子接口之下,还有着众多的实现子类或者派生的子接口,其中最常用的有:
TreeSet
LinkedHashSet
HashSet
LinkedList
ArrayList
Stack
Map系

Map集合为双列集合。Map**没有直接继承的子接口,**主要有三个实现类,分别是HashMap、HashTable、SortedMap。在三个主要实现之下,比较常用的实现及其实现子类有:
HashMap(性能高,非线程安全)
Hashtable(性能较低,线程安全,但属于老旧的API,一般不推荐使用)
TreeMap(有序map)
细说
Collection
由于Collection接口直接继承了Iterable,它是没有实现的,它的所有方法都是由它的子接口的实现类进行实现,所以这里就以Collection下子接口List的实现类ArrayList来讲解。注意List是有序集合且元素可以重复,而Set则是无序集合,元素不可重复。
讲解的方法列表
add:添加单个元素
remove:输出指定元素
contains:查找元素是否存在
size:获取元素个数
isEmpty:判断是否为空
clear:清空
addAll:添加多个元素
containsAll:查找多个元素是否都存在
removeAll:输出多个元素
基本用法演示
List list = new ArrayList();
/*添加单个元素*/
list.add("Jack");
//这里其实是一个自动装箱的操作:list.add(new Integer(10))
list.add(10);
list.add(true);
System.out.println("list:"+list);
/*输出元素*/
//输出"Jack"
//list.remove(0);
//指定输出某个元素
list.remove(true);
System.out.println("输出后的[list]:"+list);
/*查找某个元素是否存在*/
//true
System.out.println(list.contains("Jack"));
/*获取元素个数*/
//2
System.out.println(list.size());
/*判断集合是否为空*/
//false
System.out.println(list.isEmpty());
/*清空集合*/
list.clear();
//清空后的[list]:[]
System.out.println("清空后的[list]:"+list);
/*添加多个元素*/
ArrayList list2 = new ArrayList();
list2.add("西游记");
list2.add("西厢记");
list.addAll(list2);
//添加多个元素后的[list]:[西游记, 西厢记]
System.out.println("添加多个元素后的[list]:"+list);
/*判断多个元素是否都存在*/
//true
System.out.println(list.containsAll(list2));
/*输出多个元素*/
list.add("华强北");
//true
System.out.println(list.removeAll(list2));
//华强北
System.out.println(list);
遍历用法
上面的类图已经知道,
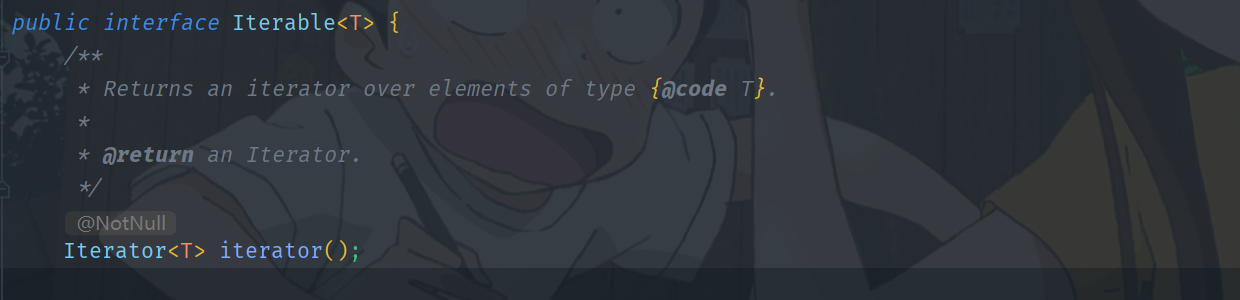
Collection接口还有一个Iterable父接口。它的部分实现源码中第一个方法如下:
可以看到,该方法可以返回元素的
iterator对象。只要是实现了接口的所有子类,都有一个iterator()方法。在对元素的遍历上,都可以采用迭代器的方式进行遍历。所以Collection及其所有子类实现,我们都可以获取到每个元素的迭代器并用在对元素的遍历操作上。需要注意的是,iterator仅用来遍历集合,本身并不存放任何对象。
迭代器的执行原理
作为
Collection的父接口,Iterator的方法如下:
我们一般在使用迭代器进行遍历的时候,都会用到一个
while循环,循环的条件是iterator.hasNext(),也就是说,在每次得到遍历元素之前,iterator对象会调用自身的hasNext()方法,对集合里的元素进行判断,只有当存在下一个元素时,迭代器才会继续往下执行,否则,迭代结束。
可以看到,
Iterator的hasNext()方法返回一个布尔值,如果该迭代对象还存在元素的情况下。这个方法就相当于一个指向集合元素的指针,每一次调用都会向下移动以检查是否到达集合尾部,在移动的同时,它还会调用next()方法,该方法会将移动后该指针指向位置上的元素进行返回。为了有效的防止空指针,每次在调用Next()之前,会先调用hasNext(),这是有必要的。如果说不存在下一个元素,则会抛出一个NoSuchElementException异常。


Iterator使用示例
package collection;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
/**
* @author: 八尺妖剑
* @date: 2022/3/20 14:17
* @description: 演示迭代器[Iterator]的使用
* @blog:www.waer.ltd
*/
@SuppressWarnings({"all"})
public class CollectionIterator {
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("C++ Primer Plus","Stephen Prata",57.4));
col.add(new Book("程序员的数学","结城浩",20.5));
col.add(new Book("Java疯狂讲义","李刚",80.7));
System.out.println("集合[col]:"+col);
/*遍历集合*/
//1.获取集合的迭代对象
Iterator iterator = col.iterator();
//2.while循环遍历数据
while(iterator.hasNext()){
//3.注意:iterator返回默认时一个Object类型(除非指定泛型)
Object o = iterator.next();
System.out.println("[col]迭代返回:"+o);
}
//4.当退出while循环之后,此时的iterator指向最后一个元素,在调用next()方法会报NoSuchElementException异常。
//如果需要再次遍历,需要重置迭代器。方法如下:
//IDEA支持快速生成迭代方法,使用[Ctrl+j]快捷键进行查看
iterator = col.iterator();
while (iterator.hasNext()) {
Object o1 = iterator.next();
System.out.println("[col]再次迭代:"+o1);
}
}
}
/**
* 内部类
*/
class Book{
private String name;
private String author;
private double price;
public Book(String name, String author, double price) {
this.name = name;
this.author = author;
this.price = price;
}
@Override
public String toString() {
return "Book{" +
"name='" + name + '\'' +
", author='" + author + '\'' +
", price=" + price +
'}';
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getAuthor() {
return author;
}
public void setAuthor(String author) {
this.author = author;
}
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
}
一些需要注意的点,已经写在了注释当中。
增强for
所谓增强for,也就是针对普通for循环的增强。它可以替代
iterator迭代器,相当于一个简化版的iterator,也正因为如此,增强for只能用于遍历集合或者数组。
基本语法:
for(元素类型 元素名:集合或者数组名){
访问元素;
}
package collection;
import java.util.ArrayList;
import java.util.Collection;
/**
* @author: 八尺妖剑
* @date: 2022/3/20 14:56
* @description: 演示增强for的使用
* @blog:www.waer.ltd
*/
public class CollectionFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
Collection col = new ArrayList();
col.add(new Book("C++ Primer Plus","Stephen Prata",57.4));
col.add(new Book("程序员的数学","结城浩",20.5));
col.add(new Book("Java疯狂讲义","李刚",80.7));
/*使用增强for进行集合的遍历*/
for(Object book:col){
System.out.println("book="+book);
}
}
}
List接口
常用实现及其方法一览

List接口是Collection的子接口,上面讲解的ArrayList的方法是来自Collection接口方法。而这些方在Set子接口中也可以使用。下面讲一下子接口List中的实现类,也是以ArrayList实现为例。
List集合类中的元素是有序(添加和取出顺序一致)的,且是可重复的。
List集合中的每一个元素都有其对应的顺序索引,即他是支持索引的一类集合。
List中的元素都对应一个整数型的序号记载其在容器中的位置,可以根据序号存取容器中的元素。
List子接口的主要常用实现类有ArrayList、LinkedList、Vector。
List的一些方法
package List;
import java.util.ArrayList;
import java.util.List;
/**
* @author: 八尺妖剑
* @date: 2022/3/20 16:57
* @description: List的方法演示
* @blog:www.waer.ltd
*/
public class ListMethod {
@SuppressWarnings({"all"})
public static void main(String[] args) {
List list =new ArrayList();
list.add("张无忌");
list.add("张天志");
/*在index位置插入元素e*/
/*注意:这里如果不指定下标的话,默认是以尾部追加的方式进行元素插入的*/
list.add(1,"Tisox");
//list=[张无忌, Tisox, 张天志]
System.out.println("list="+list);
/*addAll(inr index,Collection e):从index位置开始将元素e中的所有元素添加进来*/
List list2 =new ArrayList();
list2.add("蜘蛛侠");
list2.add("钢铁侠");
list.addAll(1,list2);
//list=[张无忌, 蜘蛛侠, 钢铁侠, Tisox, 张天志]
System.out.println("list="+list);
/*int intdexOf(Object obj):返回obj在当前集合中首次出现的位置*/
System.out.println(list.indexOf("蜘蛛侠"));
/*int lastIndexOf(Object obj):返回obj在当前集合中最后一次出现的位置*/
list.add("凋残");
System.out.println(list.lastIndexOf("凋残"));
/*remove(int index):移除指定index位置的元素,并返回此元素*/
list.remove(0);
System.out.println("list="+list);
/*set(int index,Object ele):设置指定index位置出的元素为ele,相当于是替换元素*/
list.set(1,"新的名字");
System.out.println("list="+list);
/*subList(int fromIndex,int toIndex):返回从fromIndex到toIndex位置的子集合*/
//返回一个左闭右开的区间
List reslist = list.subList(0, 2);
System.out.println("relist="+reslist);
}
}
List的三种遍历方式
由于
ArrayList、LinkedList和Vector都是List的实现子类,以下方法可以无缝切换,效果是一样的。
package List;
import java.util.*;
/**
* @author: Tisox
* @date: 2022/3/20 19:18
* @description: List的三种遍历方式
* @blog:www.waer.ltd
*/
public class ListFor {
@SuppressWarnings({"all"})
public static void main(String[] args) {
//List list =new Vector();
List list = new LinkedList();
//List list = new ArrayList();
list.add("jack");
list.add("tom");
list.add("回锅肉");
list.add("鱼香肉丝");
list.add("砂锅粉");
/*1.迭代器遍历*/
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.println("[list]的[迭代器iterator]遍历="+list);
}
System.out.println("====================================");
/*2.增强for遍历*/
for (Object o : list) {
System.out.println("[list]的[增强for]遍历="+list);
}
System.out.println("====================================");
/*3.普通for循环遍历*/
for(int i=0;i<list.size();i++){
System.out.println("[list]的[普通for循环]遍历="+list.get(i));
}
}
}
ArrayList
ArrayList允许存入null值。
ArrayList arrayList = new ArrayList();
arrayList.add(null);
arrayList.add("");
arrayList.add("Java");
System.out.println(arrayList);
底层采用数组实现。
ArrayList线程不安全

通过它的源码可以看到,他是没有
synchronized关键字修饰的。也正是因为如此,它的效率是比较高的,所以如果需要保证线程安全的场景下,不建议使用ArrayList。
源码分析
**ArrayList中维护了一个Object类型的数组elementData[]。**源码如下:
transient Object[] elementData;
这里的elementData[]数组的类型是Object类型,也就是说,它可以存放任意类型的数据,因为Object类是所有类的父类,也就是顶级父类。 关键字transient的作用是去除序列化,当某个属性被加上该关键字即表示它在进行序列化时会被忽略,不参与序列化操作。
底层扩容原理
ArrayList底层采用数组这种数据结构来实现,必然会有容量的限制,那么在它的底层是如何实现自动扩容的呢?这里以其中的add()方法进行浅析。
ArrayList有两个构造方法,分别是无参数构造和有参构造。下面是源码
//无参构造
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
//有参构造
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
两个构造方法不仅在参数上有所区别,他们的底层扩容原理也是不一样的,先看一下无参数的 ArrayList()构造。
可以看到,在无参构造的方法中,它将数组的初始容量设为DEFAULTCAPACITY_EMPTY_ELEMENTDATA。也就是一个空对象数组。这一点可以从下面的源码得知。

下面尝试在集合中添加元素,来分析add方法的执行过程。
//使用无参构造对集合进行初始化
ArrayList list = new ArrayList();
//向其中添加10个元素
for (int i = 1; i <= 10; i++) {
list.add(i);
}
执行过程和扩容原理
- 在初始化完成后,当我们触发add()时,它会先调用
valueOf()方法对添加的元素进行一个装箱操作,这不是本次分析的重点,不再赘述。注意下面这个自动装箱的源码来自JDK11

装箱结束后,进入
add(E e)这个方法,该方法是集合中的一个重载方法,接收一个泛型参数,源码如下:public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
首先,在执行正式的添加操作之前,会先执行ensureCapacityInternal()方法,该方法主要是用来确认集合的容量情况,决定是否需要扩容。再调用添加方法进行元素的添加。显然,这里出现的ensureCapacityInternal()方法是重点,源码如下:
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
ensureExplicitCapacity(minCapacity);
}
方法传入一个名为minCapacity的int类型变量,表示数组最小容量。接着判断elementData是否是DEFAULTCAPACITY_EMPTY_ELEMENTDATA默认值,由于我们选择的是无参构造,所以if语句中的条件是成立的。接下来Math.max(DEFAULT_CAPACITY, minCapacity)在默认容量和最小容量之间取一个最大值并赋给minCapacity,也就是更新minCapacity的值。关于默认容量DEFAULT_CAPACITY,下面是它的声明:
private static final int DEFAULT_CAPACITY = 10;
执行之后,minCapacity的值将更新为10;也就是说,这个方法目的是为了确认minCapacity的值,而在if之后,又出现了一个ensureExplicitCapacity(minCapacity)方法,在if判断条件不满足的情况下执行,参数就是上面更新后的minCapacity,可以猜测,这个方法应该也是对是否需要扩容进行一个判断的算法。
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
注意,这里有一条为modCount++;的语句,他主要是记录当前集合被修改的次数,为了防止被多个线程操作,否则会抛异常。第4行中if的条件minCapacity - elementData.length > 0表示最小容量与当前数组元素容量的一个差值大于0是否成立,将会直接调用下一个方法进行扩容,也就是grow()方法。
比方说,此时的
minCapacity=10,elementData=0,显然10-0>0,也即是说,数组需要一个最小容量为10空间,而此时的容量为0,显然需要进行扩容操作。
下面是grow()方法,也是扩容的核心实现。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
可以看到,方法开始会先将数组容量elementData.length赋值给一个中间变量oldCapacity。接着为变量newCapacity进行赋值,算法是将oldCapacity旧的容量+旧容量的二分之一赋值给该变量。注意这里(oldCapacity >> 1)表将oldCapacity右移一位,等同于除以2,用位运算可以提高执行效率。反过来,如果是左移的话,代表乘以2。
又由于前面已经知道elemenatData其实是等于0的,那么直接导致这条赋值语句结果为0,也就是newCapacity==0,所以它后面紧接着出现了两个判断。
如果新的容量小于最小容量,那么将最小容量赋给这个新容量,完成一次扩容,此时数组的容量由0变为10.
如果
newCapacity > MAX_ARRAY_SIZE,那么newCpapcity的值由方法hugeCapacity()决定。这个后面再说,我们继续当前的分析,在执行完上面的判断语句之后,最后对elemantData进行重新赋值,核心方法Arrays.copyOf(elementData, newCapacity),该方法的作用是将newCapacity的值复制给elementData。之后elementData里面将会存在10个null值.
就是说,当我们首次使用该集合的无参构造初始化集合时,其实并不会触发1.5倍的底层扩容机制。注意,这里使用copyOf()方法的作用也是为了保留扩容之前已经存在集合中的元素,换句话说,每次扩容并不会导致已存在的元素丢失,而是在这些元素之后添加N个值为null的元素空间。比如这样:
//null值得位置就是扩容的容量
{1,2,3,4,5,6,7,8,9,10,null,null,null,null,null}
当以上扩容操作完成之后,执行会返回到之前的add()方法:
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
此时的elementData已经由最初的空数组扩容为大小为10的容量,当执行完elementData[size++] = e;之后,新的容量中第一个位置会被替换为元素1:
[1,null,null,null,null,null,null,null,null,null]
注意理解minCapacity和elementData的含义。前者的意思时我们用这个集合存放某些元素最少需要的空间,而后者表示此时这个集合本身拥有的空间,所以,扩容的目的在于扩张elementData的大小,以满足存放minCapacity所需。
现在来看一下上面留下的**hugeCapacity(minCapacity)**方法,源码如下:
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ? Integer.MAX_VALUE : MAX_ARRAY_SIZE;
}
//注意:以下是MAX_ARRAY_SIZE的常量定义。
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
//2147483647是Integer.MAX_VALUE
这个方法其实就是对数组大小边界进行一个判断和限制,要求数组大小在0到MAX_VALUE之间。如果<0直接抛出一个OutOfMemoryError异常,否则返回一个值作为数组容量的上限,这里用了一个三元表达式作为返回语句。
如果最小容量大于MAX_ARRAY_SIZE,则将Integer.MAX_VALUE的值赋给它,否则还是用MAX_ARRAY_SIZE。
再看一下为什么这里****MAX_ARRAY_SIZE是Integer.MAX_VALUE-8,也即是**2147483647-8=2,147,483,639****而不是减其他数值?**关于这个问题,其实再源码的注释中就已经写清楚了。

大致意思就是如果直接使用Integer.MAX_VALUE的话,在某些虚拟机中,可能会出现溢出的问题。不过一般情况下,我们还是认为它的值可以直接看作是与Integer.MAX_VALUE相同。以下是来自stackoverflow的一个解答,可以参考一下。
Why the maximum array size of ArrayList is Integer.MAX_VALUE - 8?
有参构造的扩容原理
上面分析了调用无参构造器创建集合后,它底层的扩容原理,其实只要理解了之后。那么关于有参构造的扩容,就很容易理解了。
下面是它的有参构造器源码,前面也提到过。
/**
* Constructs an empty list with the specified initial capacity.
*
* @param initialCapacity the initial capacity of the list
* @throws IllegalArgumentException if the specified initial capacity
* is negative
*/
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+initialCapacity);
}
}
这段代码很容易理解,我们在调用该构造器进行初始化时传入一个初始大小initialCapacity作为数组的初始容量。如果该容量大于0,此时elementData数组会直接用该值作为数组的长度创建一个新的Object数组,以完成初始化。否则如果传入的初始值为0,会对elementData进行一个常量赋值操作,将数组初始化为EMPTY_ELEMENTDATA大小的数组,该常量定义如下:
private static final Object[] EMPTY_ELEMENTDATA = {};
也就是创建一个空数组。如果不在以上两种情况之外的,直接抛一个IllegalArgumentException异常结束。但是一般情况下,既然我们决定调用了该构造器,一般不会直接甩个0进去,这样做的意义不大。
在初始化完成后,进入添加方法,方法会先对现有的数组容量进行检查,如果发现所需最小容量大于当前初始化传入的容量,则会先进入grow()方法完成扩容,这里扩容不会进入第一个if判断,因为初始化传入的elementData必然是大于0的,程序会直接执行源码中的int newCapacity = oldCapacity + (oldCapacity >> 1);这行逻辑,直接采取1.5倍扩容的机制对数组进行扩容后,将扩容后的整个数组空间直接复制一份,该操作会在原有元素的基础上追加扩容部分的空间,该部分的值默认使用null来填充,这些和前面分析无参构造扩容时候是一样的。此时再返回添加方法内部执行添加,添加成功之后之前扩容的null部分会被刚添加的元素取代,以此类推,直到下一次容量不够时,又再一次触发1.5b倍的扩容机制。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
}
实例演示
通过一个具体的例子,来解释帮助理解上面所说的扩容原理(无参构造)。
- 无参构造器
假设我们调用 了
ArrayList()对集合list进行了初始化并尝试向其中添加元素,下面模拟这个大致过程:
初始化完成,创建一个空的对象数组
elementData[] = {}。进入
add()方法,根据当前添加元素所需空间对已有空间进行判断,显然我们添加第一个元素时,minCapacity=1,而elementData=0。此时不忙着执行添加,而是调用
ensureCapacityInternal()方法:
该方法发现,初始化的
elementData=DEFAULTCAPACITY_EMPTY_ELEMENTDATA,则执行一个Math.max()方法,该方法直接将minCapacity的值改为10。此时我们的minCapacity=10,而elementData还是0;进入**
ensureExplicitCapacity()**方法,满足判断条件发现,所需最小容量>当前容量,需要扩容,触发grow()方法。
检查并记录
elementData的长度,发现此时该值为0,由于0的1.5倍还是0,此时扩容算法无意义不执行。进入第一个
if判断,发现条件满足,直接将minCapacity的值赋给一个新的变量newCapacity=10执行数组的
copyOf()方法,将会开辟一个容量为10的数组。程序跳回
add()方法,执行元素的添加。
add()方法执行结束。
也就是说,如果我们调用无参构造器初始化集合,首次扩容并不会按照1.5倍的机制来,而是直接给你开一个大小为10的数组,只有当这10个空间全部用完之后,之后的每一次扩容,就都会采用1.5倍的机制进行扩容,因此首次调用的方法栈是比较绕的,但是从第二次开始,或者使用有参构造器初始化的时候就会少一些判断,空间不够,直接开始1.5倍扩容机制走起。
1.5倍扩容怎么算?
假设当前容量值为
8,下一次扩容的值就是12,算法过程很简单:12 = 8+8/2
\= 8+4
\=12
只不过,在源代码中,算法使用右移
>>代替除法,要知道,位运算的速度是远快于四则运算的。由此,如果需要再次扩容的话,12的容量会扩容为12+6 = 18。
Vector
基本结构
Vector类的定义,它实现自List接口。
public class Vector<E>
extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable
它的底层实现也是基于对象数组,它由protected修饰符修饰:
protected Object[] elementData;
Vector是线程安全的,它的操作方法都有synchronized修饰,该关键字可以实现线程同步和互斥,所以他是线程安全的。比如其源码中的indexOf()方法,因此,一般在开发中,如果有线程安全的需要,可以考虑使用Vector。当然,这也并非是必须的,关于线程安全的集合或者说实现,还有专门的类去管理,Vector在JDK1.0版本中就有的,算是一个老前辈了,尽管它线程安全,但也不一定就是最佳的选择。
public synchronized int indexOf(Object o, int index) {
if (o == null) {
for (int i = index ; i < elementCount ; i++)
if (elementData[i]==null)
return i;
} else {
for (int i = index ; i < elementCount ; i++)
if (o.equals(elementData[i]))
return i;
}
return -1;
}
源码分析
扩容机制
默认10满后,按照2倍扩容。如果指定大小,则每次按2倍扩容。
创建一个无参的vector之后,它会默认直接给你一个大小为10的空间。直截了当。
public Vector() {
this(10);
}
接着执行添加操作,跳转到add()方法(这里就不再提自动装箱的操作了),源码如下,咋一看是不是和前面分析的ArrayList的源码如出一辙?除了一个modCount++之外,还是会在添加元素之前先执行一个名为ensureCapacityHelper的方法,基于前面ArrayList源码的阅读理解,这里不用多想也能猜到,这个方法的作用,无非就是对目前的数组容量进行判断,看看是不是需要扩容。
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
进入ensureCapacityHelper的源码看看,可以看到这实现和ArrayList中的实现几乎一样,还是判断最小所需空间和当前数组的容量关系,显然,这里elementData=10,而minCapacity=1,不满足扩容的条件,因此这里不会进入grow()方法。直接返回add()执行元素的添加,一次添加执行结束。
private void ensureCapacityHelper(int minCapacity) {
// overflow-conscious code
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
下面我们假设,要添加第11个元素,此时原来的10个空间已经不够,自然会触发扩容机制,下面是该扩容方法的实现源码:
// 扩容方法
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 关于capacityIncrement的定义:
/**
* The amount by which the capacity of the vector is automatically
* incremented when its size becomes greater than its capacity. If
* the capacity increment is less than or equal to zero, the capacity
* of the vector is doubled each time it needs to grow.
*
* @serial
*/
protected int capacityIncrement;
根据源码了解到,它会先将elementData的长度放到一个名为oldCapacity的变量中并创建一个新的容量newCapacity,该变量的值就是扩容的核心原理,其中 int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity)这段三元表达式会先判断capacityIncrement的值是否>0,如果成立,那么capacityIncrement的值保持不变,那么整个表达式就是newCapacity = oldCapacity+capacityIncrement。
否则将会是newCapacity =oldCapacity+oldCapactity,也就newCapacity 会变为原来两倍的容量,最后依旧是采用copyOf()方法将扩容后的空间复制到原空间,完成扩容。关于其中两个if判断的逻辑和之前对ArrayList的分析是类似的,不再赘述。通过这个源码也发现了,这个2倍扩容的算法中,有一个名为capacityIncrement的容量增量,具体作用面会在下面有参构造器中进行分析。
有参构造器源码分析
该构造器的源码如下,构造器是有两个参数的,其中一个便是上面提到的容量增量参数capacityIncrement。
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
方法体首先会先调用父类的无参构造。如果我们不指定capacityIncrement的值,它默认是0,也就是无增量,一般在调用无参构造器时就是属于这种情况,**在没有明确容量增量时,扩容会按照原容量的2两倍进行,**如果指定具体的值,我们在grow()方法中看到, int newCapacity = oldCapacity + ((capacityIncrement > 0) ? capacityIncrement : oldCapacity);这个表达式将产生一个新的容量值,该值的大小由原来的容量+指定的容量增量决定。那么可能会开始疑惑, 既然说了是2倍扩容,那么加一个容量增量算怎么回事?
如果指定了该增量的值,不就改变了2倍扩容的机制了吗?其实不完全是,在vector源码中,其实存在三个构造器,上面这个便是可以指定扩容增量的构造器,如果你不需要指定第二个参数,那么还可以看到,它还有一个普通的带一个参数的构造,源码如下:
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
该构造器尽管只需要一个参数,但它在创建之后会默认给capacityIncrement赋值为0,这也就是不管你是空参构造还是带参构造对Vector进行初始化,在扩容时都会用到capacityIncrement这样一个参数,这也是扩容算法中三元表达式的意义,你可以不写,但我必须得用,所以才会有默认的0,这是不冲突的。
/*无参构造*/
Vector vector = new Vector();
/*指定一个参数:默认为集合的初始大小*/
Vector vector2 = new Vector(6);
/*指定两个参数:依次时集合大小和扩容时的容量增量*/
Vector vector3= new Vector(6,3);
LinkedList
基本结构
LinkedList底层实现采用了双向链表和双端队列。可以添加任意元素且元素可以重复(因为实现自List接口),同时包括
null。非线程安全的集合,没有实现同步。
在其中维护的两个属性
first和last分别指向首尾节点,prev指向前驱节点,next指向后继节点。因此
LinkedList的元素删除和添加的操作效率相对较高。
源码分析
[待更新……]
如何选择
如何选择使用
ArrayList和LinkedList?根据我们实际的使用场景或者需求
如果涉及改查操作比较多,建议
ArrayList。如果增删操作比较多,建议
LinkedList。一般来说,在程序中
80%~90%都是查询操作,因此大部分情况下会选择使用ArrayList。当然,选择哪一个并非一成不变,在实际的项目中,甚至可能出现
ArrayList和LinkedList同时使用的情况,也是正常的,所以要求最好都会使用。
Set接口
下面主要讲解Set子接口下的主要实现类。
常用方法和实现

Set的基本介绍
无序(元素的添加与取出的顺序不一致),无索引。
注意理解这里的无序的含义,并不是说,每一次取出的顺序都是随机的,而是指当执行了一次取出之后,今后的每一次相同的操作,它取出的元素顺序都与第一次相同,但这个顺序又和添加进去的顺序不保持一致。
不允许重复元素。
还有一点,由于它是
Collection的子接口,自然也支持其父接口中的特性,比如迭代对象,增强for等等。
HashSet
基本结构
HashSet作为Set典型的实现类之一,拥有Set的全部属性,这里不再赘述。
源码解读
初始化与基本原理
我们先看一下HashSet的基本用法,其实,HashSet在实现上,就是一个HashMap,这一点可以从它的构造器说起。
Set hashSet = new HashSet();
以下是HashSet的无参构造器源码,可以看到,当我们创建一个HashSet对象时,它在底层直接new了一个HashMap,这又不得不说一下HashMap的底层,它是由数组+链表+红黑树构成,所以相对来说是比较复杂的。

public HashSet() {
map = new HashMap<>();
}
换句话说,要分析HashSet的源码,其实就是分析HashMap的原理。HashSet一个明显的特点就是不能添加重复的元素,但这里的重复也许不是你想象中的那么简单。
下面开始分析一下其中的添加元素的add()方法在底层是如何实现的。
添加一个元素时,会先得到一个
hash值,根据该值转成一个索引值。找到存储数据表
table,检查该索引是否已在table中存在有元素:
如果没有,直接将该元素加入。
如果有,会调用
equals方法进行比较操作,如果比较结果为true,添加失败,否则,将会在末尾添加元素。在
Java8中,如果一条链表的元素个数达到TREEIFY_THRESHOLD且table的大小>=MIN_TREEIFY_CAPACITY,就会触发树化机制,即会由单链表结构转换为一棵红黑树。
为例更好的理解它的执行过程和原理,我们按照下面这几行代码来讲解:
HashSet hashSet = new HashSet();
hashSet.add("Java");
hashSet.add("C++");
hashSet.add("Java");
System.out.println("hashSet="+hashSet);
代码逻辑很简单,就是向HashSet中添加三个元素,其中有两个元素是重复的,这是为了理解它底层是如何判断元素重复的。
执行代码,首先会进入HashSet的构造器,直接创建一个值为空的HashMap,这点在上面已经说过。进入add()方法,它的实现源码如下:
//HashSet中add方法的源码实现
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
方法很简单,直接调用了map的put()方法,注意到,这个方法除了我们需要添加的元素e之外,它还有一个名为PRESENT的常量参数,关于这个参数的理解,源码中是这样介绍的:
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
PRESENT其实是一个static final修饰的对象,在上面的方法中作为put(k,v)中value的占位,并没有其他实际的作用。这里不必深究。不知道有没有注意到,add方法中将map.put(e,PRESENT)==null作为返回值,为什么这里会是null呢?这和HashMap底层实现有关系,我们先继续往下,后面自然就会明白了。下面进入put方法内部看看。
//HashSet中map.put(e,PERSENT)方法源码
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
方法中有一个putVal的方法,可以看到其中的第一个参数hash(key)表示通过这个方法获取key的hash值。这里的key也就是我们传入的待添加的元素,进入该方法:果然,hash方法的作用就是计算key的hash值,算法都在这条三元表达式当中了,可以简单看一下。
//HashMap中的hash()方法实现
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
核心算法(key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16),意思就是如果传入的key为null,那么直接返回0,也就是不执行任何实际操作。否则会使用hashCode()方法获取key的哈希码和无符号右移16位之后的值进行一个异或操作,将该异或的结果返回作为key最终的hash值。这样作主要是为了保证高16位和低16未的特征,减少碰撞,减低hash冲突的几率。
注意,hash和hashCode并不是一回事。
这里的
hash仅仅是用来在HashMap中计算key对应的散列码。它的算法中用到了hashCode()这个方法,hashCode是在Objct中定义的,用来获取每个元素对应的散列值,底层使用的C语言作为实现,属于native方法。换句话说,使用hashCode()方法可以计算Java中每一个元素的一个哈希值。而hash()方法在这里的作就相对局限,使用的算法也相对简单很多,具体的关于hash和hashCode()的内容,可以自己研究,这里不作展开。
理解了hash的计算方式之后,继续往后看,在获取到key的hash,方法会返回进入到putVal()方法中,这是整个添加操作的底层实现的核心源码,也是一个难点。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
在方法体的开始,定义了几个局部变量,以备后面使用(废话)。继续看下面的代码,这是方法体的第一个if判断,主要的作用是判断并创建一个table,注意,这里的table是一个数组+链表形式的结构,也就是数组每一个索引出的元素都是一条单链表的形式。这一点前面有提到。具体的逻辑是,
if ((tab = table) == null || (n = tab.length) == 0){
n = (tab = resize()).length;
}
首先,对于if中的(tab = table) == null 条件,程序先将table赋值给tab变量,判断集合中是否已经存在table数据,或者说该数组的长度是否为0。如果上述条件有一个成立,则表示这是第一次向集合中添加元素,hashMap会自动调用resize()方法对table[]进行首次扩容,以用来存放接下来的元素,所以,明白了这个判断的作用,也就不难推测,为什么这条if判断语句会放在方法的开始了,也可以推测,只要不是首次添加元素,就不再会进入该判断,直接走后面的逻辑。那么现在的关注点就该转移到这个resize()方法中,看一下它的源码:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
那就看下它的扩容原理吧。首先呢,如前面说所,它开始就创建了一个table[]。将该数组的引用赋给oldTab,
Node<K,V>[] oldTab = table;
注意这里这个数组首次定义并非在这个方法中,而是在HashMap源码中有做的一个定义,它也是不可被序列化的。接着会先判断该table是否是首次创建,如果是,直接初始化为0,否则就是oldTab的大小,为什么会这么说呢,因为这个resize()方法可不只是执行这一次,在putVal()方法的后续的逻辑中还会用到,也就是会出现再次扩容的情况,那么存在一个oldTab的值也就不难理解了吧。
如果oldCap>0,进一步判断它是否>=最大容量MAXNUM_CAPACITY,关于MAXNUM_CAPACITY的定义如下
//MAXIMUM_CAPACITY定义
static final int MAXIMUM_CAPACITY = 1 << 30;
如果该条件成立,会给threshod重新赋一个新的容量值,即Integer的上限,反之进入下一个判断 ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&oldCap >= DEFAULT_INITIAL_CAPACITY),将oldCap左移1位,也就是两倍的oldCap赋给一个新的变量newCap,如果该值小于MAXNUM_CAPACITY并且原来的容量oldCap大于等于初始默认容量值DEFAULT_INITIAL_CAPACITY的话,就将新的newThr扩为原来(oldThr)的两倍大小。
//DEFAULT_INITIAL_CAPACITY定义
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
//1<<4等价于1X2^4=2x2x2x2=16
这里先对上面源码中涉及到的几个变量简单说明一下,不然频繁的
=赋值操作一波又一波,可能会给整懵圈。
oldCap:数组原先(准备扩容之前)的容量。
oldThr:其实就是threshold的一个暂存局部变量,用来暂存threshold的值。
threshold:这是一个定义在HashMap的的全局变量(可以这么说,实际上Java中没有全局变量这种概念),它用来存放table[]的一个容量值,或者说阈值。所以最终决定是否需要扩容取决于这个全局变量来判断。
newCap:同理于oldCap。
继续回到最外层if判断的else if逻辑中,这里先是对newThr是否大于0作了判断,如果>0成立,那么新的容量newCap的值沿用oldThr,否则将会执行下面这段代码,newCap的值默认设置为DEFAULT_INITIAL_CAPACITY也就是16,并且newThr的值更新为(int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);。这里参与*运算的除了初始默认容量DEFAULT_INITIAL_CAPACITY外,还有一个重要的常量参数DEFAULT_LOAD_FACTOR,我们称为负载因子,换句话说,这个因子的值决定了你每次扩容的具体大小。它是默认值为0.75,也就是说当我们数组占用量达到本身容量的75%时,就会触发首次扩容(resize)操作。当然,最后还进行了强制类型转换为int。
所以不难理解,如果我们是首次使用HashMap进行put操作,方法会直接进入这一步进行初始化。
else {// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
具体一点说,当阈值达到
16*0.75时,也即是16大小的容量用掉了12个大小时就会触发首次resize。
这个负载因子不是固定不变的,而且有一点需要说明的是,这个resize()方法中,负载因子是可以手动传入的,这一点在HashMap的另一个构造方法中有体现,当然,这个后面再说。这里主要讲的还是无参构造器的执行原理,你需要理解resize()方法的两个主要作用,第一个就是上面巴拉巴拉这一堆,主要是用来对数组进行初始化工作(当然,你也可以理解为首次扩容,这只是一种说法而已,一般我们会将首次扩容称为初始化,因为其实扩容的概念是建立在已有容量的基础上的),而此后再调用resize()就执行的是扩容工作了,但它的扩容工作可没有初始化这么简单。
但为了能更清晰的理解,我们还是继续首次put操作的主线进行分析。接着上面说,初始化结束之后,会得到一个初始的阈值newThr=16,并将该阈值重新赋给全局threshold保存。计算出table[]的一个初始大小之后,利用该值直接创建一个大小为newCap的新的newTab给table返回,有了这个table,我们就可以在里面存放元素了,比如存放一个字符串Java。
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
但光是初始化一个16大小的table是远远不够的。我们知道,既然是数组里面存放元素,是需要一个索引的,根据这个索引去找到一个对应的位置,再将该元素覆盖上去,完成元素的添加。
所以我们先回到上一个方法putVal()方法:接着上面切入进来的resize()方法之后讲解。
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
上面这两行代码,也就是我们上面刚刚讲完的初始化操作的部分。
看一下,在对table进行了初始化,并计算得到key的hash之后,后续的代码逻辑分解:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
这里就是根据hash值计算一个索引i。方法是(n-1) & hash,在获得索引之后,检查该索引位置的值tab[i]赋给变量p并判断是否为null,如果为null表示没有被使用,后面一句tab[i] = newNode(hash, key, value, null);直接将元素key存进去,当然,存入的元素除了我们自己传入的数据之外,还有计算出来的hash和一个value,传入hash主要是为了下一次计算,用来确定下次传入的值是否为重复元素。至于其中还有一个值为null的值,表示链表的下一个结点指向,当然,这里是首次put,所以next是不存在的,也就是null。当上面这段代码执行完毕之后,元素就被成功添加到table中了。
通过
debug可以看到,key计算出的hash=2301537.那么这个索引就可以根据(16-1)&2301537计算出来,它的值是为1的,也就是数组中第二个位置的索引。
元素添加之后,程序逻辑会直接执行到下面的代码
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
其中的++modCount我在ArrayList源码分析的文章中已经提过,他们的作用是一样的。判断if (++size > threshold),如果添加元素之后的数组容量>目前的阈值threshold,会触发resize()。关于afterNodeInsertion(evict);方法,是HashMap留给它的子类去实现的一个方法,所以它是个空的方法。类似的方法还有:
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
接着putVal()方法最后返回一个null作为方法的结束。所以还记得前面留的一个问题吗?在HashSet源码中的add()方法的方法体里面,它的返回值是判断是否为null,再看一下吧还是。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
表示执行HashSet中的add()方法添加一个元素,它底层实际上调用了HashMap中的put()方法去实现,能否添加成功的依据就是该put()方法是否返回null,如果是,HashSet的add()方法就返回一个true,最终表示着我们利用HashSet成功的添加了一个元素。否则,添加失败!!
去重原理
在理解了
HashMap底层table[]的初始化逻辑之后,当我们向其中put()第二个元素时,它的底层是如何判断元素是否重复的呢?下面就以这个问题为主线开始分析。
由于同样是添加的操作,前面的的几个步骤就不再赘述,比如底层调用map.put(),然后是hash的计算。直接进入putVal()方法开始看。这里再贴一遍它的源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
鉴于前面我们在添加第一个元素Java的时候,已经完成了table[]的初始化工作,所以下面这段代码不会再执行;
if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length;
而是直接带着前面计算得来得Hash通过与之前同样算法计算出元素C++(假设这是我们第二个添加的元素)在数组中的索引,代码如下:
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
注意哈,这里的
n在初始化的时候已经计算出来,还是等于16的,改变的是hash值,假设为65762。那么根据上述算法计算得到它的索引为15&65762=2。
好了,既然索引也有了,并且我们添加的这个元素和第一个元素Java明显是不相等的,所以不会进入到else if判断中,因为if已经成立,后面的逻辑就是将该元素值直接添加到数组中索引为2的位置,当然,元素也是一个Node<k,v>类型。注意,这里存入参数中的最后一个值依旧还是null,因为前后两个元素并没有存放在同一条链表上,自然不会出现在尾部挂载的情况。
下面将会进行第三个元素的添加,假设我们添加的元素是
Java,是的,和首次添加的元素是相同的,看一下底层将会如何处理。
同样我们直接跳到putVal()方法中。程序首先会进入到第二个if判断里,开始计算索引并作判断,也就是下面这段代码:
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
注意了,由于首次计算得出Java对应的索引为2,那么这次的结果也是相同的值,所以if中的条件显然不可能成立,因为索引为2的位置已经被占用,自然不会为null。所以程序将会进入下面的逻辑中:
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
又是一堆if else if套娃操作。按照它的顺序,我们先分析第一个if的逻辑:
if (p.hash == hash &&((k = p.key) == key || (key != null && key.equals(k))))
e = p;
鉴于()中涉及到了三处逻辑运算,方便理解,我们将它逐层进行拆分讲解。
(k = p.key) == key || (key != null && key.equals(k))
首先看||的左边(k=p.key)==key:意思是先将p中的key值赋给变量k,再与key进行一个比较,判断是否为同一个key值(对象),注意了,这里的两个key的意思,前一个key(也就是k)**代表的是数组之前已经存在数组中的元素,**而后一个key就是当前传入的元素,具体的也就是指我们第一次存入的Java和本次存入的Java。
再看||右边(key != null && key.equals(k),这是一个&&操作,需要操作符两边的条件同时成立,整个条件才会成立。首先判断存入的key是否为null,再判断key和k是否为相同(注意这里用了equals()方法,该方法可被重写),判断是否为相同的内容。回到外层的p.hash==hash这个判断,就是将已有索引处对应的元素(元素是存在Node上的)的hash值取出与当前元素的Hash进行比较。
所以归纳起来也就是当二者hash相同并且key也相同(同一个对象)的情况下,执行e=p赋值操作,将原位置的值进行覆盖。
如果上面的条件不成立,会判断p是否是红黑树,如果是,就调用对应的添加方法putTreeVal()进行添加,也就是下面的代码。这里的 instanceof关键字用来判断一个对象是否为一个类的实例。另外,putTreeVal()方法内部涉及到大量红黑树的代码,相对复杂很多,如果跳进去的话,估计一时半会出不来,所以这里暂时不作探究,会另外分开来学习,还是围绕着主线继续分析。
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
否则,进入else逻辑中:
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
开局一个for,目的明确,既然上面两种情况都不成立,那么说明该元素可能会在某一条链表节点上出现,比如下面这样:
Java->C++->Javascript->Java
所以我们需要以遍历的方式去检查链表上的每一个节点,循环内部,通过p和e两个指针不停的循环比较。
如果过程中发现有一个和当前元素重复的元素,循环会立即结束,元素添加失败,否则就将当前元素直接挂到节点后面,完成添加。注意其中这段代码:
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
//TREEIFY_THRESHOLD的定义
static final int TREEIFY_THRESHOLD = 8;
这是在进行添加之后对当前这条链表进行一个判断,如果长度>=(TREEIFY_THRESHOLD=8)-1的话,会调用treeifBin()方法对当前链表进行树化(转红黑树),但是注意,光是这个条件满足还不足以开始树化,在这个方法的实现中,还添加了其他的添加用来判断,treeifBin()源码:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
就是说,就算前面的条件(>=8)已经成立,这里还会进行一个判断,具体逻辑如下:
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
它还会判断当前这个table的大小是否<MIN_TREEIFY_CAPACITY也就是是否<64。如果这个条件成立,那么会先对数组进行一个resize()扩容操作,而不是直接转红黑树。最后如果添加失败,会返回一个之前元素的value值。
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
扩容原理
前面对整个流程有了大致的了解之后,下面主要针对它的扩容原理进行一个简单的总结。
关于扩容的原理,先说结论:
HashSet底层是HashMap,首次添加时,table数组的容量扩为16,初始临界值为12:threshold(阈值) = table.size()(table数组大小) * loadFactor(加载因子)
\=16*0.75
\=12
如果
table数组使用的部分达到了阈值,就会触发扩容,具体的扩容为16*2=32,也就是会按照两倍的扩容方式进行,基于这个容量再次计算新的扩容阈值:32*0.75=24,也就是如果本次扩容后的容量(32)使用达到24之后,就会再次触发下一次的2倍扩容机制,以此类推。
简单来说,以上就是HashSet(本质HashMap)的扩容原理,具体的,看下面源码分析。
在resize()方法中有这样一段代码
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
可以看到,新的容量是在原有容量的基础作了一个左移的操作,也就是和乘2是等效的,但用位运算效率会快很多。
这是在pustVal()源码的部分代码:
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
resize();就是触发扩容时调用的扩容方法。具体的源码前面有讲过,不再赘述。
在Java8中,如果一条链表的元素个数达到 TREEIFY_THRESHOLD且此时table的大小>=MIN_TREEIFY_CAPACITY
时就会触发链表转红黑树的操作。提高性能。
上面涉及到的两个常量在源代码中的定义如下:
static final int TREEIFY_THRESHOLD = 8;
static final int MIN_TREEIFY_CAPACITY = 64;
转红黑树的方法源码如下,这里只需要看看大致的执行逻辑就好,关于红黑树具体的实现,不是本章的主要内容。
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
注意如果只是满足链表长度达到8的条件时,它还是会采用resize()方法对数组扩容,而不是直接转红黑树。
注意了!!
上面提到的触发数组扩容的条件中,
size的大小大于负载因子才会触发,这里的size指的是数组和链表中元素的和,也就是只要我们向其中添加一个元素,不论这个元素是存在数组第一个位置,还是存在链表中某个位置,size都会自增1,这是一个比较容易搞错的地方,不要认为size就是指数组的长度,这是错误的。
为什么不直接使用hash来计算索引,而是要进行取模运算?
如果将哈希码映射到数组中的一个索引。可能会因为
hash值过大而因此导致索引超出范围。所以一个最简单的方法是对哈希码和数组的长度进行模运算,如hash(key) % n。如此可以确保索引i总是在0和n之间。
但是Java在实现的时候,用的并不是上面说的算法,而是将数组的长度n减去1之后再与hash作&运算得到,实现代码如下:
i = (n - 1) & hash;
LinkedHashSet
概述
LinkedHashSet是Set接口的一个实现子类,也是HashSet的子类。LinkedHashSet的底层是一个LinkedHashMap,底层维护了一个数组+双向链表。LinkedHashSet根据元素的hashCode值来决定元素的存储位置,同时使用链表来维护元素的次序,这就使得元素看起来是以插入的顺序保存的。其次,
LinkedHashSet也不允许添加重复元素。

在LinkedHashSet中维护了一个hash表和双向链表,每一个节点有pre和next属性,这样可以形成双向链表。在添加元素时,先求hash值,再求索引,确定该元素在哈希表中的位置,然后将添加的元素加入到双向链表(如果已经存在,不添加(原理和hashset类似))。
源码解读
- 通过下面的示例来配合讲解:
Set set = new LinkedHashSet();
set.add("A");
set.add(120);
set.add(120);
set.add(new User("李",1001));
set.add(123);
set.add(new String("hello"));
System.out.println(set);
如果断点的方式,我们可以看到,LinkedHashSet的一个基本结构如下:

通过上图可以发现,其中存在一个tail和head的属性,这是典型的双向链表中才会用到的两个引用,或者指针(c/c++),代表双向链表的头尾指针。即进一步验证了前面提到的LinkedHashSet的是一个HashTable和双向链表的组合。
其中的table类型其实是一个HashMap$Node[]类型,而每一个节点又是维护的LinkedHashMap$Entry[]类型。

为什么数组为HashMap$Node[]数组类型而存放的元素却是LinkedHashMap$Entry[]类型?
说明
LinkedHashMap$Entry[]肯定继承或者实现了HashMap$Node[]的,即通过数组多态的方式实现。注意这里的$符号标识$之后的类作为$之前的一个静态内部类,也即表示在LinkedHashMap$Entry中,Entry是LinkedHashMap的一个静态内部类。
在LinkdeHashMap中我们可以找到对应的源码验证。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
从上述的源码中不仅说明Entry是LinkedHashMap的内部类,也说明LinkedHashMap$Entry[]继承了HashMap$Node[]。
其中有两个Entry<K,V>类型的属性:before和after,可以理解为两个引用,主要用来完成各节点之间的连接。
同样,我们也可以通过查看HashMap的源码,验证上面的说法:Node同样作为其一个静态的内部类实现。并且该类还实现了其父接口Map中的Entry<K,V>。
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}

在存储元素时,每一个元素中依然是使用的key来存储,而value只是一个object类型的占位符,这里没有实际的意义。因为在LinkedHashSet中,我们不需要显式的去像Map中存一个K,V形式的值。
- 当我们添加一个重复元素时,
LinkedHashSet会直接调用父类HashSet中的比较方法,对重复元素进行一个判断并去重,其实这里的原理和之前讲的HashSet原理是一样的,当添加元素是,LinkedHashSet还是会直接调用父类HashSet中的add()方法(该方法本质还是调用HashMap中的put()方法),接着是putVal()关于这两个方法的源码在前面讲HashSet源码的时候就已经讲过,这里不再赘述。所以说,经管是不同的结构实现,但在元素判重的原理上其实使用的还是同一个逻辑。
说白了,LinkedHashSet本质上大部分还是HashMap
LinkedHashset底层维护了一个LinkedHashMap结构,这一点可以类比于HashSet底层维护一个HashMap来进行对比记忆。而前面我们已经知道,LinkedHashMap其实就是HashMap的一个子类。对于
LinkedHashSet我们在理解了前面HashSet源码的基础上,只需要理解它底层的一个实现结构即可,也就是数组+双向链表的结构,回到一开始的哪个示例中,我们向set集合中添加了:
“A”,120, User,123
之后,通过断点的方式可以看到他们之间的一个指向关系如下

上图展示了内部元素节点中
after和before的引用关系。仔细观察每一个LinkedHashMap$Entry后都会跟一个@number的标识,**这是用来标识该位置元素的一个唯一标记,或者你也可以理解为该元素在该结构中的一个地址。**因此,我们可以用该标识来唯一性的代表一元素值,注意其中每一各after或者before的指向关系,具体在后面我回画个图帮助理解。
- 再跳出元素内部
Entry,我们看到在table中有两个名为head和tail的引用属性。用来标识该双向链表的头尾节点。

将上面的逻辑以图片的形式展示出来大概就是下面这样:

简单捋一下:
每向
LinkedHashSet中添加一个元素,首先会根据该元素计算一个hash值,用来确定它在上面图中table数组中的索引位置。通过上面的步骤添加多个元素之后,元素内部是一个
Entry[]类型的结构,其中每一个元素都有一个after和before属性,用来指向它的前一个元素和后一个元素的位置。再通过两个属性
head和tail来指向整个链表的头和尾,从而构成一个完整的含有头尾指针(引用)的双向链表。将该链表具象化出来可以大致表示为图中右边部分。换句话说,这里的
after和before其实就相当于平时常用的pre和next指针,即前驱后继指针,只不过命名不同而已,没什么高深莫测的。注意,和前面
HashSet的数组+单链表的结构类似,每一个索引位都可以是一条完整的双向链表,就像图中索引为7的位置一样,而不是每个索引为只能有一个链表节点,这取决于元素计算出来的hash。正是由于双向链表的特性,使得我们添加的元素顺序是相对有序的,也就是添加的顺序和打印出来的顺序是一样的。
关于扩容
首先,LinkedHashSet如果使用无参数构造器初始化,那么它默认会开辟一个16大小的空间,负载因子依旧是0.74,首次扩容的阈值为12。这些数值是不是很眼熟?如果你看了前面HashSet的源码分析的话。
public LinkedHashSet() {
super(16, .75f, true);
}
虽然讲的是LinkdeHashSet,但本质上分析的还是HashSet,再本质就是LinkedHashMap,再继续套娃你会发现,就是讲的HashMap,可见这家伙才是主角。
未完待续……